逻辑回归(Logistic Regression)原理与实现详解
逻辑回归是机器学习中最基础、最常用的分类算法之一。尽管名字中带有“回归”,但它解决的是分类问题,尤其适用于二分类任务。本文将从背景动机出发,系统讲解其核心原理、数学推导,并提供从零实现与 scikit-learn 调用的完整示例。
一、为什么需要逻辑回归?
线性回归擅长预测连续值(如房价、温度),但无法直接用于分类任务。例如:
- 判断邮件是否为垃圾邮件(0 或 1)
- 预测肿瘤是否为恶性(良性/恶性)
若强行使用线性回归:
- 输出可能小于 0 或大于 1,无法解释为“概率”
- 对异常值敏感,决策边界不稳定
逻辑回归通过引入 Sigmoid 函数,将线性输出映射到 (0,1) 区间,使其可自然解释为样本属于正类的概率,从而完美衔接回归思想与分类任务。
二、模型原理
给定输入特征向量 \mathbf{x} = [x_1, x_2, \dots, x_n]^T,逻辑回归首先计算线性组合:
z = \mathbf{w}^T \mathbf{x} + b
其中 \mathbf{w} 为权重向量,b 为偏置项。
随后,通过 Sigmoid 函数(又称 Logistic 函数)进行非线性变换:
\sigma(z) = \frac{1}{1 + e^{-z}}
最终预测结果为:
\hat{y} = P(y=1 \mid \mathbf{x}) = \sigma(\mathbf{w}^T \mathbf{x} + b)
由于 \sigma(z) \in (0,1),\hat{y} 可直接视为“属于类别 1 的概率”。
决策规则
- 若 \hat{y} \geq 0.5,预测为 1
- 若 \hat{y} < 0.5,预测为 0
对应的决策边界为:
\mathbf{w}^T \mathbf{x} + b = 0
这是一个线性超平面(在二维空间中为一条直线)。
三、数学推导
1. 概率建模
假设标签 y \in \{0,1\} 服从伯努利分布,则条件概率可写为:
P(y \mid \mathbf{x}; \mathbf{w}, b) = [\sigma(z)]^y [1 - \sigma(z)]^{1 - y}
2. 极大似然估计
设训练集为 \{(\mathbf{x}^{(i)}, y^{(i)})\}_{i=1}^m,似然函数为:
L(\mathbf{w}, b) = \prod_{i=1}^m [\sigma(z^{(i)})]^{y^{(i)}} [1 - \sigma(z^{(i)})]^{1 - y^{(i)}}
取对数似然以简化计算:
\ell(\mathbf{w}, b) = \sum_{i=1}^m \left[ y^{(i)} \log \sigma(z^{(i)}) + (1 - y^{(i)}) \log (1 - \sigma(z^{(i)})) \right]
3. 损失函数(交叉熵)
最大化对数似然等价于最小化其负值。定义平均损失函数为:
J(\mathbf{w}, b) = -\frac{1}{m} \sum_{i=1}^m \left[ y^{(i)} \log \hat{y}^{(i)} + (1 - y^{(i)}) \log (1 - \hat{y}^{(i)}) \right]
此即二元交叉熵损失(Binary Cross-Entropy Loss)。
4. 梯度计算
令 \hat{y}^{(i)} = \sigma(z^{(i)}),可推导出梯度为:
\frac{\partial J}{\partial w_j} = \frac{1}{m} \sum_{i=1}^m (\hat{y}^{(i)} - y^{(i)}) x_j^{(i)}
\frac{\partial J}{\partial b} = \frac{1}{m} \sum_{i=1}^m (\hat{y}^{(i)} - y^{(i)})
5. 参数更新
采用梯度下降法更新参数(学习率为 \alpha):
w_j := w_j - \alpha \cdot \frac{\partial J}{\partial w_j}
b := b - \alpha \cdot \frac{\partial J}{\partial b}
值得注意的是,该梯度形式与线性回归高度相似,区别仅在于 \hat{y}^{(i)} 是 Sigmoid 输出。
四、Python 实现
1. 从零实现(NumPy)
import numpy as np
from sklearn.datasets import make_classification
# 生成模拟数据
X, y = make_classification(
n_samples=200, n_features=2, n_redundant=0, n_informative=2, n_clusters_per_class=1, random_state=42)
# 添加偏置项(将 b 合并到权重向量中)
X_b = np.c_[np.ones((X.shape[0], 1)), X]
def sigmoid(z):
# 使用 clip 防止指数溢出
return 1 / (1 + np.exp(-np.clip(z, -250, 250)))
def compute_loss(y_true, y_pred):
epsilon = 1e-15 y_pred = np.clip(y_pred, epsilon, 1 - epsilon) return -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
# 初始化参数
np.random.seed(42)
theta = np.random.randn(X_b.shape[1]) # [b, w1, w2]
# 超参数
learning_rate = 0.1
epochs = 1000
# 梯度下降
losses = []
for epoch in range(epochs):
z = X_b.dot(theta) y_pred = sigmoid(z) loss = compute_loss(y, y_pred) losses.append(loss) gradient = (1 / len(y)) * X_b.T.dot(y_pred - y)
theta -= learning_rate * gradient
print("训练完成!参数:", theta)
2. 使用 scikit-learn
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
model = LogisticRegression()
model.fit(X, y)
y_pred_sk = model.predict(X)
print("sklearn 准确率:", accuracy_score(y, y_pred_sk))
print("sklearn 参数: w =", model.coef_, "b =", model.intercept_)
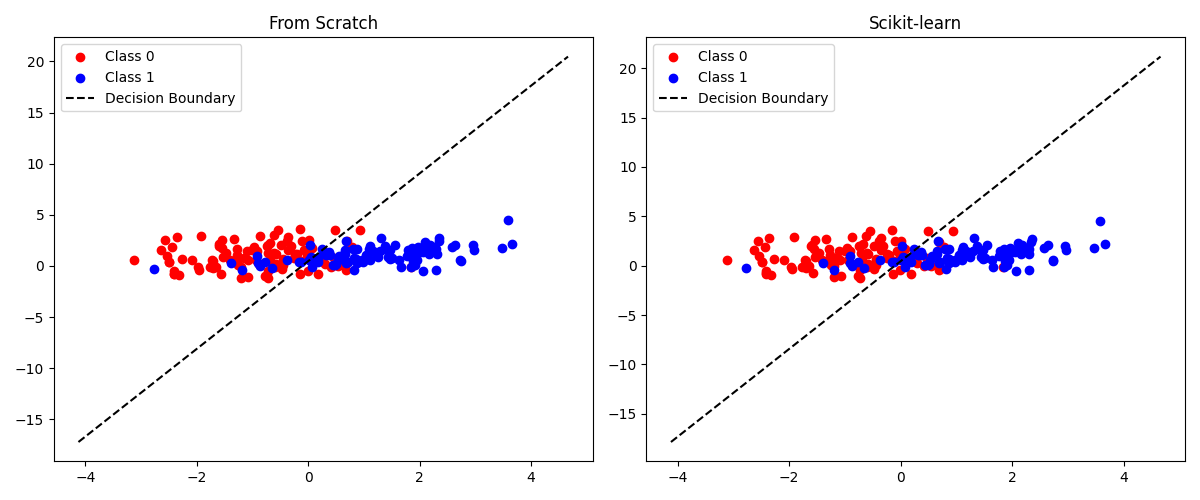
3. 两种方法的可视化决策
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 5))
# 手写模型
plt.subplot(1, 2, 1)
plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red', label='Class 0')
plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue', label='Class 1')
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x1_vals = np.linspace(x1_min, x1_max, 100)
x2_vals = -(theta[0] + theta[1] * x1_vals) / theta[2]
plt.plot(x1_vals, x2_vals, 'k--', label='Decision Boundary')
plt.title('From Scratch')
plt.legend()
# sklearn 模型
plt.subplot(1, 2, 2)
plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red', label='Class 0')
plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue', label='Class 1')
coef = model.coef_[0]
intercept = model.intercept_[0]
x2_vals_sk = -(intercept + coef[0] * x1_vals) / coef[1]
plt.plot(x1_vals, x2_vals_sk, 'k--', label='Decision Boundary')
plt.title('Scikit-learn')
plt.legend()
plt.tight_layout()
plt.show()
五、总结
| 项目 | 说明 |
|---|---|
| 任务类型 | 二分类 |
| 输出 | P(y=1∣x)∈(0,1) |
| 激活函数 | Sigmoid |
| 损失函数 | 二元交叉熵 |
| 优化方法 | 梯度下降 |
| 决策边界 | 线性 |
| 优点 | 概率输出、可解释性强、训练高效 |
| 局限 | 仅能学习线性可分边界 |